%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pymc3 as pm
import pandas as pd
import theano
import seaborn as sns
sns.set_style('whitegrid')
np.random.seed(123)
data = pd.read_csv('../data/radon.csv')
data['log_radon'] = data['log_radon'].astype(theano.config.floatX)
county_names = data.county.unique()
county_idx = data.county_code.values
n_counties = len(data.county.unique())Hierarchical models are underappreciated. Hierarchies exist in many data sets and modeling them appropriately adds a boat load of statistical power (the common metric of statistical power). I provided an introduction to hierarchical models in a previous blog post: Best Of Both Worlds: Hierarchical Linear Regression in PyMC”, written with Danne Elbers. See also my interview with FastForwardLabs where I touch on these points.
Here I want to focus on a common but subtle problem when trying to estimate these models and how to solve it with a simple trick. Although I was somewhat aware of this trick for quite some time it just recently clicked for me. We will use the same hierarchical linear regression model on the Radon data set from the previous blog post, so if you are not familiar, I recommend to start there.
I will then use the intuitions we’ve built up to highlight a subtle point about expectations vs modes (i.e. the MAP). Several talks by Michael Betancourt have really expanded my thinking here.
The intuitive specification
Usually, hierachical models are specified in a centered way. In a regression model, individual slopes would be centered around a group mean with a certain group variance, which controls the shrinkage:
with pm.Model() as hierarchical_model_centered:
# Hyperpriors for group nodes
mu_a = pm.Normal('mu_a', mu=0., sd=100**2)
sigma_a = pm.HalfCauchy('sigma_a', 5)
mu_b = pm.Normal('mu_b', mu=0., sd=100**2)
sigma_b = pm.HalfCauchy('sigma_b', 5)
# Intercept for each county, distributed around group mean mu_a
# Above we just set mu and sd to a fixed value while here we
# plug in a common group distribution for all a and b (which are
# vectors of length n_counties).
a = pm.Normal('a', mu=mu_a, sd=sigma_a, shape=n_counties)
# Intercept for each county, distributed around group mean mu_a
b = pm.Normal('b', mu=mu_b, sd=sigma_b, shape=n_counties)
# Model error
eps = pm.HalfCauchy('eps', 5)
# Linear regression
radon_est = a[county_idx] + b[county_idx] * data.floor.values
# Data likelihood
radon_like = pm.Normal('radon_like', mu=radon_est, sd=eps, observed=data.log_radon)# Inference button (TM)!
with hierarchical_model_centered:
hierarchical_centered_trace = pm.sample(draws=5000, tune=1000, njobs=4)[1000:]Auto-assigning NUTS sampler...
Initializing NUTS using advi...
Average ELBO = -1,090.4: 100%|██████████| 200000/200000 [00:37<00:00, 5322.37it/s]
Finished [100%]: Average ELBO = -1,090.4
100%|██████████| 5000/5000 [01:15<00:00, 65.96it/s] pm.traceplot(hierarchical_centered_trace);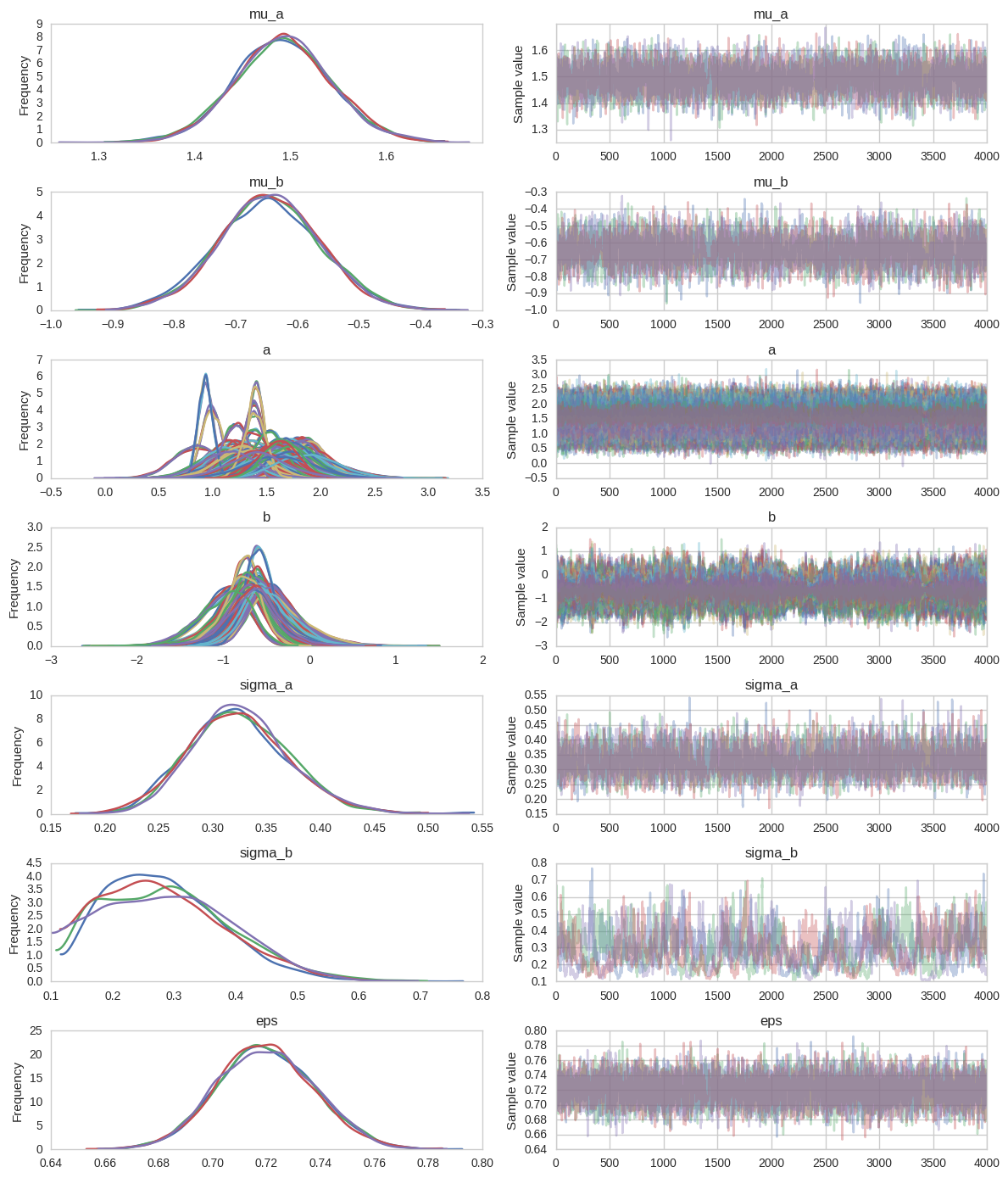
I have seen plenty of traces with terrible convergences but this one might look fine to the unassuming eye. Perhaps sigma_b has some problems, so let’s look at the Rhat:
print('Rhat(sigma_b) = {}'.format(pm.diagnostics.gelman_rubin(hierarchical_centered_trace)['sigma_b']))Rhat(sigma_b) = 1.0008132807924583Not too bad – well below 1.01. I used to think this wasn’t a big deal but Michael Betancourt in his StanCon 2017 talk makes a strong point that it is actually very problematic. To understand what’s going on, let’s take a closer look at the slopes b and their group variance (i.e. how far they are allowed to move from the mean) sigma_b. I’m just plotting a single chain now.
fig, axs = plt.subplots(nrows=2)
axs[0].plot(hierarchical_centered_trace.get_values('sigma_b', chains=1), alpha=.5);
axs[0].set(ylabel='sigma_b');
axs[1].plot(hierarchical_centered_trace.get_values('b', chains=1), alpha=.5);
axs[1].set(ylabel='b');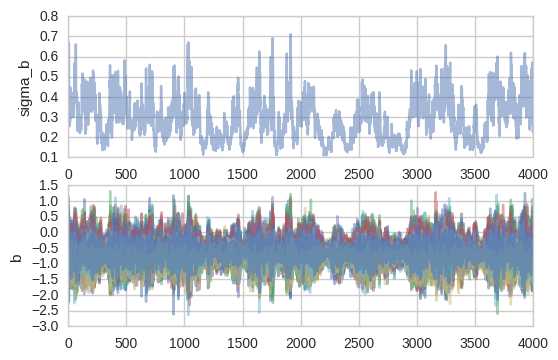
sigma_b seems to drift into this area of very small values and get stuck there for a while. This is a common pattern and the sampler is trying to tell you that there is a region in space that it can’t quite explore efficiently. While stuck down there, the slopes b_i become all squished together. We’ve entered The Funnel of Hell (it’s just called the funnel, I added the last part for dramatic effect).
The Funnel of Hell (and how to escape it)
Let’s look at the joint posterior of a single slope b (I randomly chose the 75th one) and the slope group variance sigma_b.
x = pd.Series(hierarchical_centered_trace['b'][:, 75], name='slope b_75')
y = pd.Series(hierarchical_centered_trace['sigma_b'], name='slope group variance sigma_b')
sns.jointplot(x, y, ylim=(0, .7));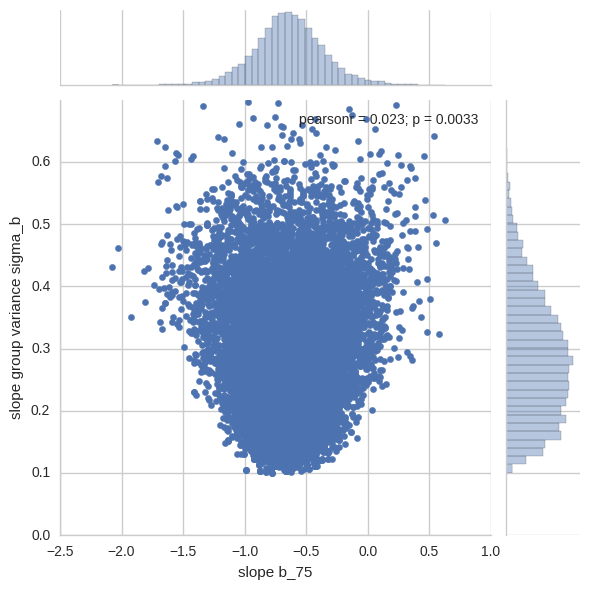
This makes sense, as the slope group variance goes to zero (or, said differently, we apply maximum shrinkage), individual slopes are not allowed to deviate from the slope group mean, so they all collapose to the group mean.
While this property of the posterior in itself is not problematic, it makes the job extremely difficult for our sampler. Imagine a Metropolis-Hastings exploring this space with a medium step-size (we’re using NUTS here but the intuition works the same): in the wider top region we can comfortably make larger jumps to explore the space efficiently. However, once we move to the narrow bottom region we can change b_75 and sigma_b only by tiny amounts. This causes the sampler to become trapped in that region of space. Most of the proposals will be rejected because our step-size is too large for this narrow part of the space and exploration will be very inefficient.
You might wonder if we could somehow choose the step-size based on the denseness (or curvature) of the space. Indeed that’s possible and it’s called Riemannian HMC. It works very well but is quite costly to run. Here, we will explore a different, simpler method.
Finally, note that this problem does not exist for the intercept parameters a. Because we can determine individual intercepts a_i with enough confidence, sigma_a is not small enough to be problematic. Thus, the funnel of hell can be a problem in hierarchical models, but it does not have to be. (Thanks to John Hall for pointing this out).
Reparameterization
If we can’t easily make the sampler step-size adjust to the region of space, maybe we can adjust the region of space to make it simpler for the sampler? This is indeed possible and quite simple with a small reparameterization trick, we will call this the non-centered version.
with pm.Model() as hierarchical_model_non_centered:
# Hyperpriors for group nodes
mu_a = pm.Normal('mu_a', mu=0., sd=100**2)
sigma_a = pm.HalfCauchy('sigma_a', 5)
mu_b = pm.Normal('mu_b', mu=0., sd=100**2)
sigma_b = pm.HalfCauchy('sigma_b', 5)
# Before:
# a = pm.Normal('a', mu=mu_a, sd=sigma_a, shape=n_counties)
# Transformed:
a_offset = pm.Normal('a_offset', mu=0, sd=1, shape=n_counties)
a = pm.Deterministic("a", mu_a + a_offset * sigma_a)
# Before:
# b = pm.Normal('b', mu=mu_b, sd=sigma_b, shape=n_counties)
# Now:
b_offset = pm.Normal('b_offset', mu=0, sd=1, shape=n_counties)
b = pm.Deterministic("b", mu_b + b_offset * sigma_b)
# Model error
eps = pm.HalfCauchy('eps', 5)
radon_est = a[county_idx] + b[county_idx] * data.floor.values
# Data likelihood
radon_like = pm.Normal('radon_like', mu=radon_est, sd=eps, observed=data.log_radon)Pay attention to the definitions of a_offset, a, b_offset, and b and compare them to before (commented out). What’s going on here? It’s pretty neat actually. Instead of saying that our individual slopes b are normally distributed around a group mean (i.e. modeling their absolute values directly), we can say that they are offset from a group mean by a certain value (b_offset; i.e. modeling their values relative to that mean). Now we still have to consider how far from that mean we actually allow things to deviate (i.e. how much shrinkage we apply). This is where sigma_b makes a comeback. We can simply multiply the offset by this scaling factor to get the same effect as before, just under a different parameterization. For a more formal introduction, see e.g. Betancourt & Girolami (2013).
Critically, b_offset and sigma_b are now mostly independent. This will become more clear soon. Let’s first look at if this transform helped our sampling:
# Inference button (TM)!
with hierarchical_model_non_centered:
hierarchical_non_centered_trace = pm.sample(draws=5000, tune=1000, njobs=4)[1000:]Auto-assigning NUTS sampler...
Initializing NUTS using advi...
Average ELBO = -1,086.3: 100%|██████████| 200000/200000 [00:42<00:00, 4678.99it/s]
Finished [100%]: Average ELBO = -1,086.3
100%|██████████| 5000/5000 [01:05<00:00, 76.81it/s] pm.traceplot(hierarchical_non_centered_trace, varnames=['sigma_b']);
That looks much better as also confirmed by the joint plot:
fig, axs = plt.subplots(ncols=2, sharex=True, sharey=True)
x = pd.Series(hierarchical_centered_trace['b'][:, 75], name='slope b_75')
y = pd.Series(hierarchical_centered_trace['sigma_b'], name='slope group variance sigma_b')
axs[0].plot(x, y, '.');
axs[0].set(title='Centered', ylabel='sigma_b', xlabel='b_75')
x = pd.Series(hierarchical_non_centered_trace['b'][:, 75], name='slope b_75')
y = pd.Series(hierarchical_non_centered_trace['sigma_b'], name='slope group variance sigma_b')
axs[1].plot(x, y, '.');
axs[1].set(title='Non-centered', xlabel='b_75');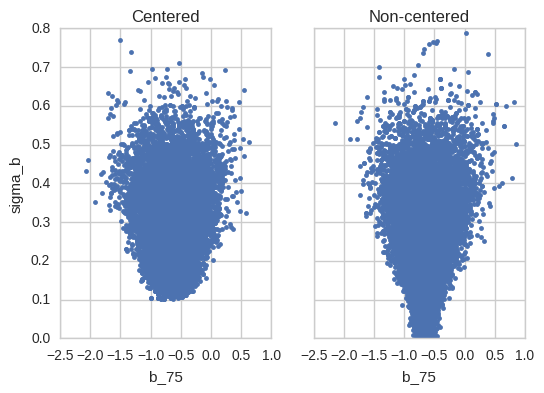
To really drive this home, let’s also compare the sigma_b marginal posteriors of the two models:
pm.kdeplot(np.stack([hierarchical_centered_trace['sigma_b'], hierarchical_non_centered_trace['sigma_b'], ]).T)
plt.axvline(hierarchical_centered_trace['sigma_b'].mean(), color='b', linestyle='--')
plt.axvline(hierarchical_non_centered_trace['sigma_b'].mean(), color='g', linestyle='--')
plt.legend(['Centered', 'Non-cenetered', 'Centered posterior mean', 'Non-centered posterior mean']);
plt.xlabel('sigma_b'); plt.ylabel('Probability Density');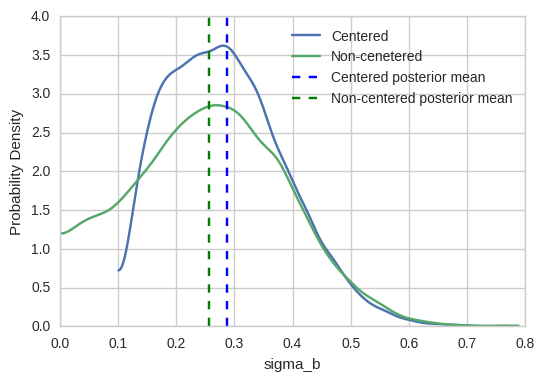
That’s crazy – there’s a large region of very small sigma_b values that the sampler could not even explore before. In other words, our previous inferences (“Centered”) were severely biased towards higher values of sigma_b. Indeed, if you look at the previous blog post the sampler never even got stuck in that low region causing me to believe everything was fine. These issues are hard to detect and very subtle, but they are meaningful as demonstrated by the sizable difference in posterior mean.
But what does this concretely mean for our analysis? Over-estimating sigma_b means that we have a biased (=false) belief that we can tell individual slopes apart better than we actually can. There is less information in the individual slopes than what we estimated.
Why does the reparameterized model work better?
To more clearly understand why this model works better, let’s look at the joint distribution of b_offset:
x = pd.Series(hierarchical_non_centered_trace['b_offset'][:, 75], name='slope b_offset_75')
y = pd.Series(hierarchical_non_centered_trace['sigma_b'], name='slope group variance sigma_b')
sns.jointplot(x, y, ylim=(0, .7))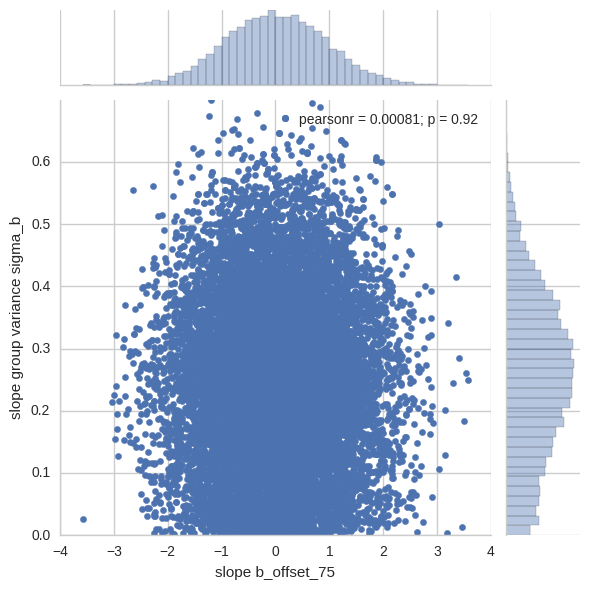
This is the space the sampler sees; you can see how the funnel is flattened out. We can freely change the (relative) slope offset parameters even if the slope group variance is tiny as it just acts as a scaling parameter.
Note that the funnel is still there – it’s a perfectly valid property of the model – but the sampler has a much easier time exploring it in this different parameterization.
Why hierarchical models are Bayesian
Finally, I want to take the opportunity to make another point that is not directly related to hierarchical models but can be demonstrated quite well here.
Usually when talking about the perils of Bayesian statistics we talk about priors, uncertainty, and flexibility when coding models using Probabilistic Programming. However, an even more important property is rarely mentioned because it is much harder to communicate. Ross Taylor touched on this point in his tweet:
It's interesting that many summarize Bayes as being about priors; but real power is its focus on integrals/expectations over maxima/modes
— Ross Taylor (@rosstaylor90) February 2, 2017
Michael Betancourt makes a similar point when he says “Expectations are the only thing that make sense.”
But what’s wrong with maxima/modes? Aren’t those really close to the posterior mean (i.e. the expectation)? Unfortunately, that’s only the case for the simple models we teach to build up intuitions. In complex models, like the hierarchical one, the MAP can be far away and not be interesting or meaningful at all.
Let’s compare the posterior mode (i.e. the MAP) to the posterior mean of our hierachical linear regression model:
with hierarchical_model_centered:
mode = pm.find_MAP()Warning: Desired error not necessarily achieved due to precision loss.
Current function value: 61.050344
Iterations: 271
Function evaluations: 639
Gradient evaluations: 628mode['b']array([-0.55116832, -0.5510971 , -0.55099195, -0.55130643, -0.55106109,
-0.55115461, -0.55112362, -0.55119258, -0.55104429, -0.5512051 ,
-0.55114496, -0.55114496, -0.5511508 , -0.5512777 , -0.55119324,
-0.55114424, -0.55113423, -0.55117297, -0.55128944, -0.55114537,
-0.5510844 , -0.55109543, -0.55110008, -0.55107659, -0.5510031 ,
-0.55111241, -0.55122769, -0.55108571, -0.551153 , -0.551153 ,
-0.55114919, -0.55115461, -0.55114591, -0.55119342, -0.55114335,
-0.55098206, -0.55113125, -0.55120426, -0.55114561, -0.55111164,
-0.55119807, -0.55114949, -0.55117142, -0.5511623 , -0.55106664,
-0.55114764, -0.55120021, -0.55118716, -0.55111885, -0.55119044,
-0.55115575, -0.55114704, -0.55104494, -0.55115026, -0.55120391,
-0.55106962, -0.55110085, -0.55113685, -0.55100548, -0.55115134,
-0.55102259, -0.55102426, -0.55112731, -0.55113959, -0.55114758,
-0.55107683, -0.55122119, -0.55114323, -0.55114537, -0.5512411 ,
-0.55112761, -0.55114537, -0.55114508, -0.55115497, -0.5511409 ,
-0.55128932, -0.55109388, -0.55103493, -0.55124849, -0.55115312,
-0.55128187, -0.55115318, -0.5510177 , -0.55107367, -0.55114537], dtype=float32)np.exp(mode['sigma_b_log_'])6.2456231e-05As you can see, the slopes are all identical and the group slope variance is effectively zero. The reason is again related to the funnel. The MAP only cares about the probability density which is highest at the bottom of the funnel.
But if you could only choose one point in parameter space to summarize the posterior above, would this be the one you’d pick? Probably not.
Let’s instead look at the Expected Value (i.e. posterior mean) which is computed by integrating probability density and volume to provide probabilty mass – the thing we really care about. Under the hood, that’s the integration performed by the MCMC sampler.
hierarchical_non_centered_trace['b'].mean(axis=0)array([-0.61611807, -0.78092307, -0.64165854, -0.68841439, -0.61489558,
-0.6457985 , -0.4308877 , -0.62139744, -0.49358603, -0.71702331,
-0.64619285, -0.64893192, -0.64824373, -0.71124178, -0.64579517,
-0.6516571 , -0.77146596, -0.53472733, -0.73048705, -0.65253747,
-0.60749978, -0.66110498, -0.62695962, -0.64096129, -0.44352376,
-0.72808003, -0.59980237, -0.63602114, -0.64530277, -0.64896953,
-0.64670545, -0.65083879, -0.6489408 , -0.67746311, -0.61535358,
-0.49529266, -0.63188666, -0.58562446, -0.58538008, -0.6389668 ,
-0.54574209, -0.64858466, -0.97170395, -0.79605013, -0.75736654,
-0.64772964, -0.80362427, -0.58304429, -0.81581676, -0.64943445,
-0.64846551, -0.65119493, -0.68078244, -0.81814855, -0.57400912,
-0.76642621, -0.67549431, -0.58657515, -0.70921665, -0.64912546,
-0.44253612, -0.40165231, -0.53912127, -0.67386925, -0.65072191,
-0.60702908, -0.43231946, -0.64889932, -0.64528513, -0.59851515,
-0.74303883, -0.65120745, -0.65097374, -0.6483686 , -0.53270531,
-0.64558667, -0.75945342, -0.7114749 , -0.7093727 , -0.7816456 ,
-0.47423342, -0.64831948, -0.94108379, -0.66192859, -0.64943826], dtype=float32)hierarchical_non_centered_trace['sigma_b'].mean(axis=0)0.25659895Quite a difference. This also explains why it can be a bad idea to use the MAP to initialize your sampler: in certain models the MAP is not at all close to the region you want to explore (i.e. the “typical set”).
This strong divergence of the MAP and the Posterior Mean does not only happen in hierarchical models but also in high dimensional ones, where our intuitions from low-dimensional spaces gets twisted in serious ways. This talk by Michael Betancourt makes the point quite nicely.
So why do people – especially in Machine Learning – still use the MAP/MLE? As we all learned in high school first hand, integration is much harder than differentation. This is really the only reason.
Final disclaimer: This might provide the impression that this is a property of being in a Bayesian framework, which is not true. Technically, we can talk about Expectations vs Modes irrespective of that. Bayesian statistics just happens to provide a very intuitive and flexible framework for expressing and estimating these models.
See here for the underlying notebook of this blog post.
Acknowledgements
Thanks to Jon Sedar for helpful comments on an earlier draft.
Dependencies
%load_ext watermark
%watermark -dmvgp numpy,scipy,pandas,matplotlib,seaborn,patsy,pymc3,theano,joblib07/02/2017
CPython 3.5.2
IPython 5.1.0
numpy 1.11.2
scipy 0.18.1
pandas 0.19.1
matplotlib 1.5.3
seaborn 0.7.1
patsy 0.4.1
pymc3 3.0
theano 0.7.0
joblib 0.10.3
compiler : GCC 4.8.2 20140120 (Red Hat 4.8.2-15)
system : Linux
release : 4.4.0-59-generic
machine : x86_64
processor : x86_64
CPU cores : 4
interpreter: 64bit
Git hash : 5d2767de3bbae72c7de7965f2afcb533df8e7ad3